
Breaking Down AI Barriers: The Power of Transfer Learning
Breaking Down AI Barriers: The Power of Transfer Learning
If you’re interested in training your own AI model for natural language processing (NLP) or computer vision, you should familiarize yourself with transfer learning and how to use pre-trained models.
MUO VIDEO OF THE DAY
SCROLL TO CONTINUE WITH CONTENT
Without transfer learning, training an effective and reliable model will often be a resource-prohibitive endeavor, requiring lots of money, time, and expertise, with ChatGPT developer OpenAI estimated to have spent millions training GPT-3, GPT-3.5, and GPT-4. With the power of transfer learning, you can train your own model as powerful as the latest GPT model with little resources in a short period.
What Is AI Transfer Learning?
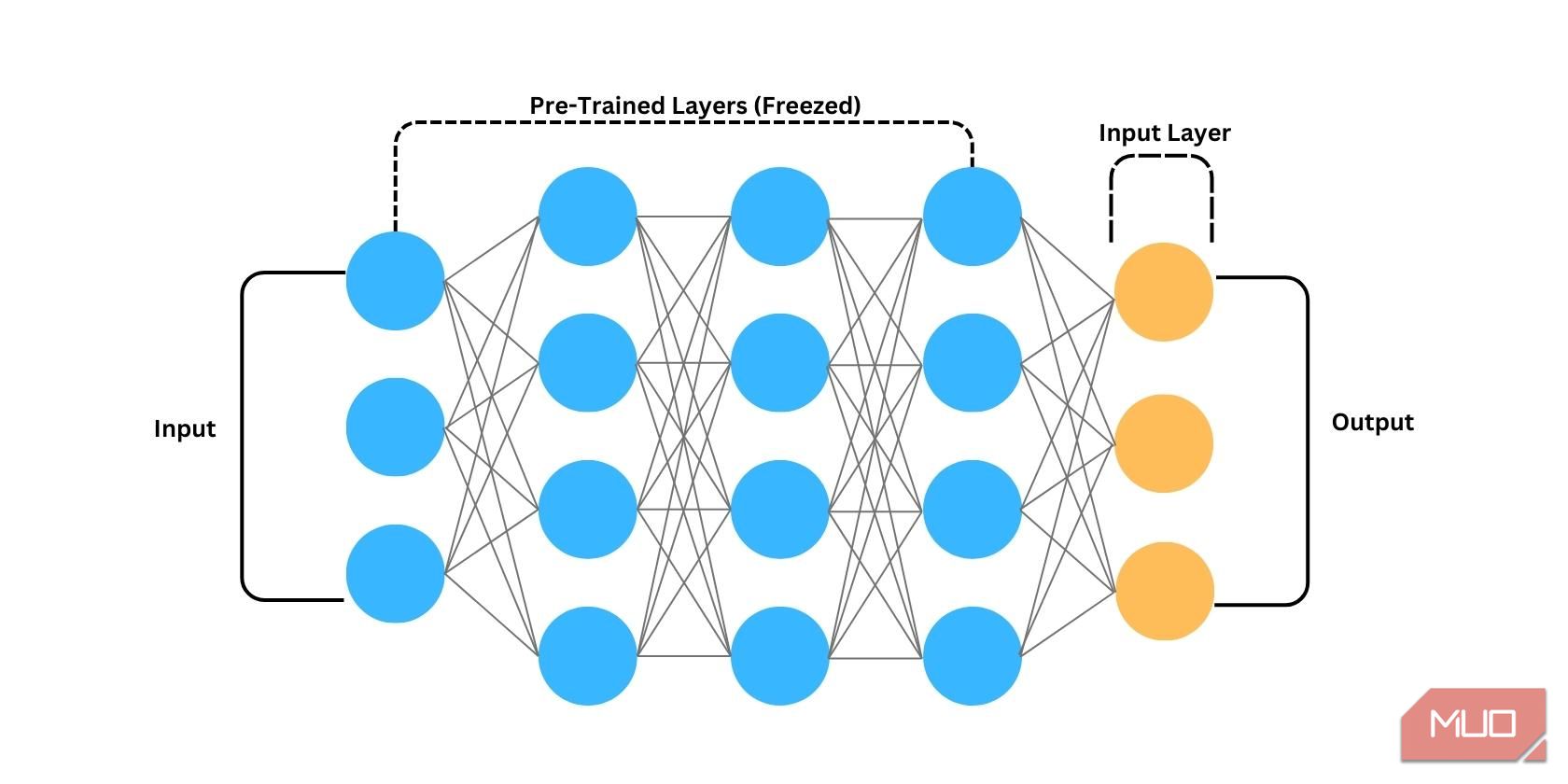
Transfer learning is the idea of taking a pre-trained model such as BERT or one of the different GPT models and training it on a custom dataset to work on tasks it wasn’t necessarily trained to tackle.
For example, you can take a pre-trained model for classifying different cat species and train it to classify dogs. Through transfer learning, training your dog-classifying model should take significantly less time and resources to become as reliable as the original cat-classifying model.
This works since cats and dogs share many traits the pre-trained model can already identify. Since the cat-classifying model can identify the various traits of a cat, such as having four legs, fur coats, and prominent snouts, the dog-classifying model can skip all the training to identify those traits and inherit them from the original model. After inheriting all those neural networks, you then cut off the last layers of the trained model used to identify the more specific traits of a cat and replace them with a dataset specific to dogs.
What AI Models Can You Use for Transfer Learning?
To use transfer learning, you’ll need a pre-trained model. A pre-trained model is commonly known as an AI model trained for the purpose of gaining general knowledge on a particular subject or idea. These types of pre-trained models are purposely made for people to fine-tune and make more application-specific models. Some of the most popular pre-trained models are for NLP, like BERT and GPT , and computer vision, such as VGG19 and Inceptionv3.
Although popular, these easily fine-tunable models aren’t the only ones you can use for transfer learning. You can also use models trained on tasks more specific than general object or language recognition. As long as the model has developed neural networks applicable to the model you’re trying to train, you can use just about any model for transfer learning.
You can get publicly available pre-trained models from places like TensorFlow Hub, Hugging Face, and the OpenAI model marketplace.
Benefits of Using AI Transfer Learning
Transfer learning provides several benefits over training an AI model from scratch.
- Reduced Training Time: When training a model from scratch, a large part of the training process is spent on general foundational knowledge. Through transfer learning, your model automatically inherits all of this foundational knowledge, thus significantly reducing training time.
- Less Resource Requirement: Since all the foundational knowledge is already there, all you need to do is to further train the model for the specifics of your application. This often only requires a relatively small data set that can be processed with less computing power.
- Improved Performance: Unless you spend millions of dollars on building your model from scratch, you cannot expect a model as good or reliable as a large language model (LLM) from a giant tech company. By using transfer learning, you can leverage the powerful capabilities of these pre-trained LLMs, such as GPT, to enhance your model’s performance.
Training an AI model from scratch is possible, but you need greater resources to do so.
How Does Transfer Learning Work?
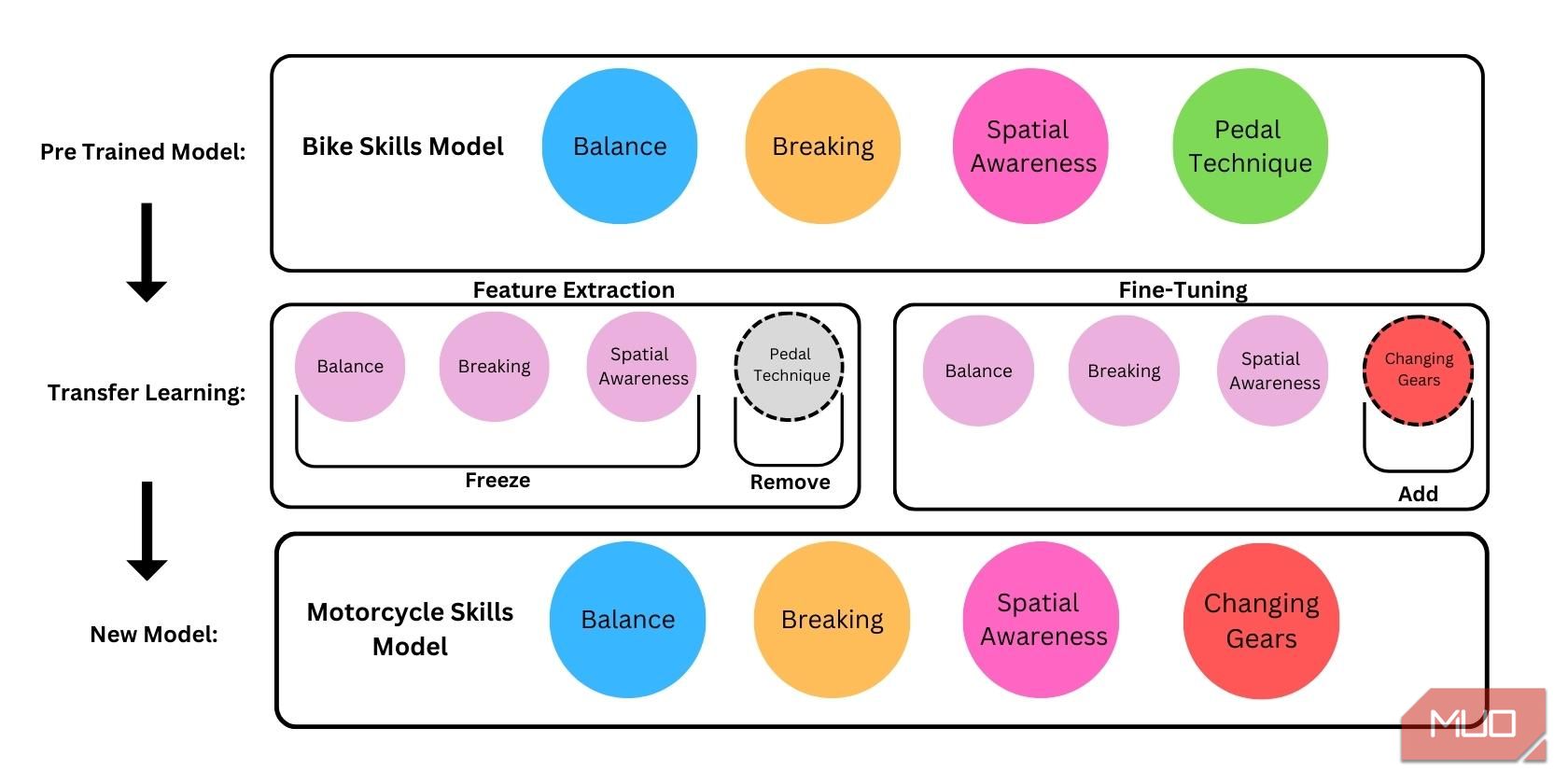
In essence, there are three stages when it comes to transfer learning.
- Selecting a Pre-Trained Model: A pre-trained model undergoes initial training using a sizable dataset from a source task, such as ImageNet, or a large collection of text. This initial training phase enables the model to acquire knowledge of general features and patterns found in the dataset. The amount of time and resources you save from transfer learning will depend on the similarities between the pre-trained model and the model you are trying to build.
- Feature Extraction: Once a pre-trained model has been selected for fine-tuning, the initial layers of the pre-trained model (closest to the input) are frozen; this means their weights are kept fixed during fine-tuning. Freezing these layers retain the general knowledge learned during the pre-training phase and prevents them from being heavily influenced by the target model’s tasks-specific dataset. For models fully trained for specific applications, the final layers of the models are removed or unlearned for the target model to be trained in other specific applications.
- Fine-Tuning: After the pre-trained model has been frozen and the top layers removed, a new dataset is fed to the learning algorithm, which is then used to train the new model and the specifics of its application.
There is more to it than the three stages, but this outline details roughly how the AI transfer learning process works, with some fine-tuning.
Limitations to AI Transfer Learning
Although transfer learning is a valuable concept in training effective and reliable models, there are quite a few limitations that you need to know when using transfer learning to train a model.
- Task Mismatch: When choosing a base model for transfer learning, it needs to be as relevant as possible to the problems the new model will solve. Using a model that classifies cats to create a dog-classifying model is more likely to yield better results than using a car-classifying model to create a model for plants. The more relevant the base model to the model you’re trying to build, the more time and resources you will save throughout the transfer learning process.
- Dataset Bias: Although pre-trained models are often trained in large datasets, there is still a possibility that they developed a particular bias during their training. Using the highly biased base model would also cause the model to inherit its biases, thus reducing your model’s accuracy and reliability. Unfortunately, the origin of these biases is hard to pinpoint due to the black-box nature of deep learning.
- Overfitting: One of the main benefits of transfer learning is that you can use a relatively small dataset to train a model further. However, training the model on a dataset that is too small may cause overfitting, which significantly reduces model reliability when provided with new data.
So while transfer learning is a handy AI learning technique, limitations exist, and it isn’t a silver bullet.
Should You Use Transfer Learning?
Ever since the availability of pre-trained models, transfer learning has always been used to make more specialized models. There’s really no reason not to use transfer learning if there’s already a pre-trained model relevant to the problems your model will be solving.
Although it is possible to train a simple machine learning model from scratch, doing so on a deep learning model will require lots of data, time, and skill, which won’t make sense if you can repurpose an existing model similar to the one you plan to train. So, if you want to spend less time and money in training a model, try training your model through transfer learning.
SCROLL TO CONTINUE WITH CONTENT
Without transfer learning, training an effective and reliable model will often be a resource-prohibitive endeavor, requiring lots of money, time, and expertise, with ChatGPT developer OpenAI estimated to have spent millions training GPT-3, GPT-3.5, and GPT-4. With the power of transfer learning, you can train your own model as powerful as the latest GPT model with little resources in a short period.
Also read:
- [Updated] 2024 Approved Instagram's Hidden Gems Tips for Viral Content Creation
- [Updated] The Art of Haul Video Production and Editing Techniques
- AI Architects at Work: Exploring the Skilled Professionals Shaping Tomorrow's Technology with ZDNet
- AI's Impact on Employment: Discovering Emerging Job Roles with Ambiguous Titles | ZDNET Insights
- Beginning Your Career in Technology: A Step-by-Step Guide for Newcomers by ZDNet
- Fixing AOC External Screen Connection Errors for Seamless Use with Windows 11
- Full Guide to Fix iToolab AnyGO Not Working On Oppo Reno 10 5G | Dr.fone
- Mastering the Art of Remote Work: Proven Strategies for Maintaining Sharp Focus at Home, Insights From ZDNET Experts
- Navigating Career Choices: Why Picking Computer Science Can Lead to Fewer Regrets | ZDNet
- Navigating the First Month of Your Remote Position - A Step-by-Step Weekly Breakdown
- Renewable Rush at FB: Complete Energy Overhaul for the Future
- Unlock iPhone 14 Pro lock with iTunes
- Unveiling the Powerhouse: An In-Depth Review of Linksys Velop's Advanced Connectivity
- Title: Breaking Down AI Barriers: The Power of Transfer Learning
- Author: Brian
- Created at : 2025-01-18 20:57:45
- Updated at : 2025-01-24 17:11:37
- Link: https://tech-savvy.techidaily.com/breaking-down-ai-barriers-the-power-of-transfer-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.