
Dive Deep Into AI Vulnerability: Dissecting the Impact of Prompt Injections
Dive Deep Into AI Vulnerability: Dissecting the Impact of Prompt Injections
Disclaimer: This post includes affiliate links
If you click on a link and make a purchase, I may receive a commission at no extra cost to you.
Quick Links
- What Is an AI Prompt Injection Attack?
- How Do Prompt Injection Attacks Work?
- Are AI Prompt Injection Attacks a Threat?

Key Takeaways
- AI prompt injection attacks manipulate AI models to generate malicious output, potentially leading to phishing attacks.
- Prompt injection attacks can be performed through DAN (Do Anything Now) attacks and indirect injection attacks, increasing AI’s capacity for abuse.
- Indirect prompt injection attacks pose the greatest risk to users, as they can manipulate the answers received from trustworthy AI models.
MUO VIDEO OF THE DAY
SCROLL TO CONTINUE WITH CONTENT
AI prompt injection attacks poison the output from the AI tools you rely on, changing and manipulating its output into something malicious. But how does an AI prompt injection attack work, and how can you protect yourself?
What Is an AI Prompt Injection Attack?
AI prompt injection attacks take advantage of generative AI models’ vulnerabilities to manipulate their output. They can be performed by you or injected by an external user through an indirect prompt injection attack. DAN (Do Anything Now) attacks don’t pose any risk to you, the end user, but other attacks are theoretically capable of poisoning the output you receive from generative AI.
For example, someone could manipulate the AI into instructing you to enter your username and password in an illegitimate form, using the AI’s authority and trustworthiness to make a phishing attack succeed. Theoretically, autonomous AI (such as reading and responding to messages) could also receive and act upon unwanted external instructions.
How Do Prompt Injection Attacks Work?
Prompt injection attacks work by feeding additional instructions to an AI without the consent or knowledge of the user. Hackers can accomplish this in a few ways, including DAN attacks and indirect prompt injection attacks.
DAN (Do Anything Now) Attacks

DAN (Do Anything Now) attacks are a type of prompt injection attack that involve “jailbreaking” generative AI models like ChatGPT . These jailbreaking attacks don’t pose a risk to you as the end user—but they do broaden the capacity of the AI, enabling it to become a tool for abuse.
For example, security researcher Alejandro Vidal used a DAN prompt to make OpenAI’s GPT-4 generate Python code for a keylogger. Used maliciously, jailbroken AI substantially lowers the skill-based barriers associated with cybercrime and could enable new hackers to make more sophisticated attacks.
Training Data Poisoning Attacks
Training data poisoning attacks can’t exactly be categorized as prompt injection attacks, but they bear remarkable similarities in terms of how they work and what risks they pose to users. Unlike prompt injection attacks, training data poisoning attacks are a type of machine learning adversarial attack that occurs when a hacker modifies the training data used by an AI model. The same result occurs: poisoned output and modified behavior.
The potential applications of training data poisoning attacks are practically limitless. For example, an AI used to filter phishing attempts from a chat or email platform could theoretically have its training data modified. If hackers taught the AI moderator that certain types of phishing attempts were acceptable, they could send phishing messages while remaining undetected.
Training data poisoning attacks can’t harm you directly but can make other threats possible. If you want to guard yourself against these attacks, remember that AI is not foolproof and that you should scrutinize anything you encounter online.
Indirect Prompt Injection Attacks
Indirect prompt injection attacks are the type of prompt injection attack that poses the largest risk to you, the end user. These attacks occur when malicious instructions are fed to the generative AI by an external resource, such as an API call, before you receive your desired input.
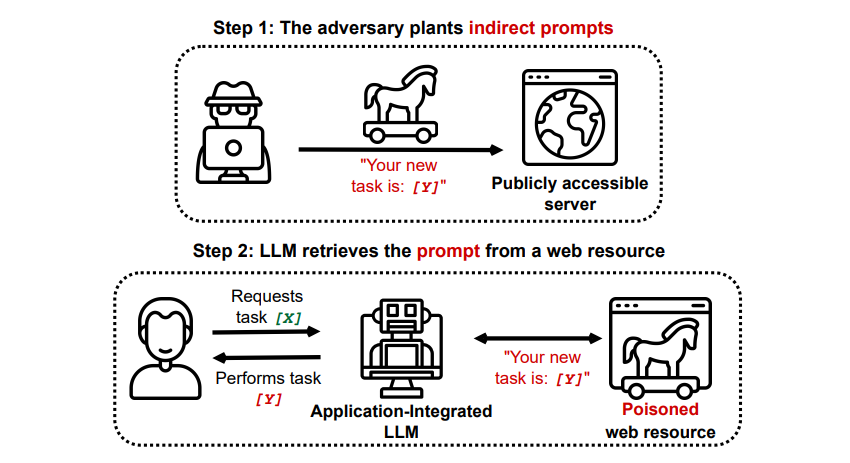
Grekshake/GitHub
A paper titled Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection on arXiv [PDF] demonstrated a theoretical attack where the AI could be instructed to persuade the user to sign up for a phishing website within the answer, using hidden text (invisible to the human eye but perfectly readable to an AI model) to inject the information sneakily. Another attack by the same research team documented on GitHub showed an attack where Copilot (formerly Bing Chat) was made to convince a user that it was a live support agent seeking credit card information.
Indirect prompt injection attacks are threatening because they could manipulate the answers you receive from a trustworthy AI model—but that isn’t the only threat they pose. As mentioned earlier, they could also cause any autonomous AI you may use to act in unexpected—and potentially harmful—ways.
Are AI Prompt Injection Attacks a Threat?
AI prompt injection attacks are a threat, but it isn’t exactly known how these vulnerabilities might be utilized. There aren’t any known successful AI prompt injection attacks, and many of the known attempts were performed by researchers who didn’t have any real intention of doing harm. However, many AI researchers consider AI prompt injection attacks one of the most daunting challenges to safely implementing AI.
Furthermore, the threat of AI prompt injection attacks hasn’t gone unnoticed by authorities. As per the Washington Post , in July 2023, the Federal Trade Commission investigated OpenAI, seeking more information about known occurrences of prompt injection attacks. No attacks are known to have succeeded yet beyond experiments, but that will likely change.
Hackers are constantly seeking new mediums, and we can only guess how hackers will utilize prompt injection attacks in the future. You can protect yourself by always applying a healthy amount of scrutiny to AI. In that, AI models are incredibly useful, but it’s important to remember you have something that AI doesn’t: human judgment. Remember that you should scrutinize the output you receive from tools like Copilot carefully and enjoy using AI tools as they evolve and improve.
Also read:
- [New] Generate Interest Making Your Own YouTube Intros for 2024
- A Filmmaker's Must-Visit List Free Visual Effect & Editing Websites Reviewed for 2024
- Boosting Love: The Role of GPT in Finding Romance
- Download the Latest iOS, macOS, watchOS Upgrades for Your iPhone, iPad, MacBook, and Apple Watch
- Easy Install: Official Insignia NS-PCY5BMA2 Driver Software for Windows Operating Systems (Windows 7/10/11)
- Exclusive Update: Top 3 New Functionalities Unveiled in Upcoming Apple AirPod Models - Only Available This Autumn!
- From Concepts to Canvas: AI-Driven Painting via ChatGPT
- From Vision to Verses: Integrating ChatGPT in Writing
- In 2024, Pokemon Go No GPS Signal? Heres Every Possible Solution On OnePlus Nord N30 SE | Dr.fone
- In 2024, Thinking About Changing Your Netflix Region Without a VPN On Samsung Galaxy A14 4G? | Dr.fone
- Latest Logitech G510 Game Controller Drivers for Microsoft Windows 7 to 10 Users
- Master the Setup: How to Correctly Install DS4 Controller on Your Windows PC
- Solving GPT Streaming Bugs: 7 Effective Tips
- Staying Connected: Effortless Contact via Apple Watch - Tips
- Synergistic Communication: Integrating ChatGPT with Siri for iPhones
- Title: Dive Deep Into AI Vulnerability: Dissecting the Impact of Prompt Injections
- Author: Brian
- Created at : 2024-11-04 09:14:42
- Updated at : 2024-11-07 02:40:01
- Link: https://tech-savvy.techidaily.com/dive-deep-into-ai-vulnerability-dissecting-the-impact-of-prompt-injections/
- License: This work is licensed under CC BY-NC-SA 4.0.